Un método neuronal para la imputación de valores faltantes en bases de datos



Las redes neuronales profundas son las campeonas de aproximar patrones complejos en un conjunto de datos lo cual para un científico de datos no es más que no sub-ajustar, es decir aproximar correctamente el conjunto de entrenamiento. En algunos casos (muchos de ellos muy conocidos como ChatGPT, AlphaGo, AlphaFold, etc...) es posible que no sobre-ajusten estas redes neuronales a pesar de estar sobre-parametrizadas.
Como un ejercicio para algunos de nuestros alumnos que están aprendiendo redes neuronales profundas en el Colegio de Matemáticas Bourbaki hemos construido un caso de uso para completar los valores faltantes en una base de datos. En este pequeño artículo vamos a describir brevemente la idea de este método.
El problema de los valores faltantes
En el análisis de datos, uno de los desafíos más comunes es tratar con valores faltantes en un conjunto de datos. La falta de datos es un problema común que aparece en contextos reales y puede comprometer el rendimiento de la mayoría de los modelos de aprendizaje. Los valores faltantes pueden surgir por diversas razones, como errores en la recopilación de datos, la no disponibilidad de información o incluso decisiones del sistema de almacenamiento de datos.

Estos valores ausentes pueden afectar negativamente el rendimiento de los modelos de aprendizaje automático, especialmente si son una parte significativa del conjunto de datos. Si no se abordan adecuadamente, los valores faltantes pueden generar sesgos, disminuir la precisión de los modelos y afectar la generalización de las predicciones.
Existen varios enfoques para manejar los valores faltantes, y los métodos clásicos suelen ser los primeros recursos utilizados para este propósito. Entre los métodos más comunes se encuentran:
- Imputación por media, moda o muestreo: Consiste en reemplazar los valores faltantes con la media (para variables ordenadas) o la moda (para variables no-ordenadas) de los datos no faltantes. Aunque es un enfoque sencillo que puede estar justificado en la ley de los grandes números, no es un enfoque que utiliza el resto de la estructura en la base de datos. También es posible rellenar con un muestreo de una distribución aproximada correspondiente, ya sea ordenada o no. La desventaja de este método es que nos estamos concentrando únicamente en las columnas de manera independiente y no en sus posibles interacciones.
- Imputación por regresión: Utiliza una técnica de regresión para predecir los valores faltantes basándose en las relaciones existentes entre las variables. Este enfoque puede ser más preciso que la imputación por media, pero depende de poder elegir correctamente la variable predictora.
- Imputación por el valor más cercano (KNN): Este método usa los valores observados más cercanos a los faltantes para estimar los valores ausentes. Si bien es una técnica potente en algunos casos, puede ser computacionalmente costosa y no siempre captura las relaciones más complejas entre las variables.
- Imputación Multivariante por Ecuaciones Encadenadas (MICE): Es un enfoque estadístico que ofrece una imputación de valores faltantes mediante un proceso iterativo, utilizando un modelo de imputación distinto para cada variable con datos faltantes. Este método trabaja encadenando ecuaciones de regresión multivariante, donde cada variable con valores faltantes se modela condicionalmente a las demás variables, y se imputan los valores faltantes utilizando las predicciones de este modelo. MICE se adapta bien a situaciones en las que las relaciones entre las variables son complejas, ya que tiene en cuenta las interacciones entre las mismas. El método que se propone en este trabajo es un poco similar.
Como en todos los problemas de machine learning, los enfoques clásicos tienen limitaciones, especialmente cuando las interacciones entre las diferentes variables no se consideran adecuadamente debido a los mismos valores faltantes. Es aquí donde las redes neuronales, pueden ofrecer una mejora significativa en la imputación de valores faltantes, considerando no solo las características individuales de las variables, sino también sus relaciones subyacentes.
Estrategia para la imputación de datos con autoencoders
Supongamos que tenemos acceso a un conjunto de datos con valores faltantes al que llamaremos X_{train}, al que un experto (o un histórico) le ha imputado algunos de los valores faltantes. A este nuevo conjunto lo llamaremos Y_{train}, quizás este conjunto aún tiene valores faltantes. Podremos suponer que este rellenado de los valores se hizo por medio de un proceso costoso como una auditoría por ejemplo.

La estrategia consiste en llenar los datos faltantes de Y_{train} mediante algún método ingenuo (con promedios, por ejemplo) para construir Y_{train}'.
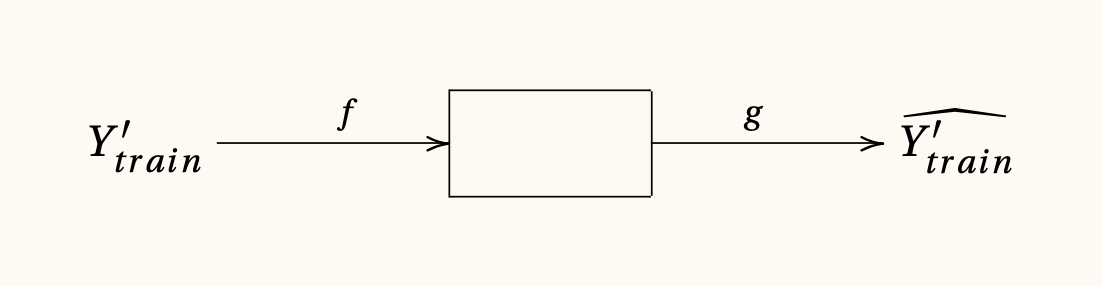
Ahora entrenaremos un modelo neuronal como un auto-encoder que arroje una transformación f a un conjunto de variables latentes; y otra transformación g al conjunto de variables originales. Nuestra intención es aprender una nueva representación del conocimiento de experto.
Utilizando una imputación de datos ingenua para X_{train}, digamos X_{train}'; podemos evaluar las funciones f y g para construir las predicciones de imputación como lo vemos en el siguiente diagrama:
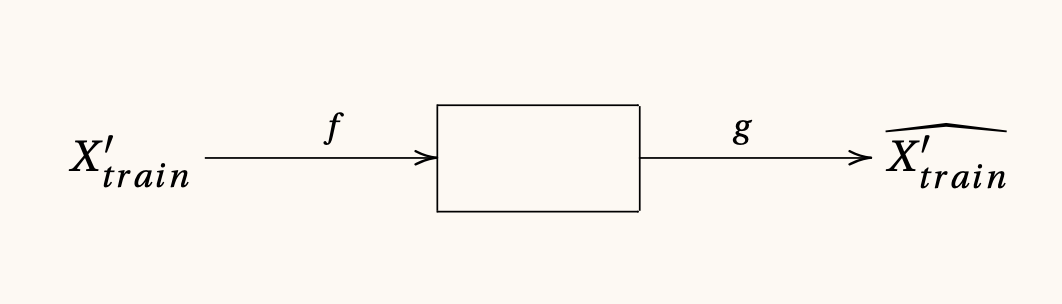
Idealmente las funciones f y g que han aprendido la representación del conocimiento del experto están forzando a X_{train}' a meterse en la representación en pocas dimensiones. La evaluación del modelo en el conjunto de entrenamiento hará comparando esta predicción en contra de Y_{train}'.
Cuando recibamos un nuevo conjunto de datos X_{test}, podemos imputar datos ingenuamente y obtener X_{test}'. Con las funciones f y g lograremos hacer una predicción para los valores faltantes. Si tenemos un conjunto Y_{test} entonces se puede estudiar el sobre-ajuste de este método.
En algunos casos estos métodos nos dan mejores resultados que los métodos clásicos que hemos mencionado inicialmente. No hemos estudiado teóricamente este algoritmo propuesto sin embargo es un excelente ejemplo de cómo se pueden aprovechar a las redes neuronales profundas.
¿Dónde aprender ciencia de datos?
En el Colegio de Matemáticas Bourbaki enseñamos con detalle las matemáticas y las bases para que nuestros estudiantes estén listos para aprender los modelos más avanzados de Inteligencia Artificial, Ciencia de Datos y Finanzas Cuantitativas. Estos son los dos cursos que están por comenzar y durarán todo el 2025.
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).




