Premio Turing 2025 a RL: Andrew Barto & Richard Sutton


Alfonso Ruiz


El día de hoy los científicos de la computación Andrew Barto y Richard Sutton recibieron el Premio Turing 2025 el cual es el más prestigioso en Ciencias de la Computación y viene acompañado por 1 millón de dólares financiados por Google. El premio cita al desarrollo de los Algoritmos de Aprendizaje por Refuerzo (RL) desarrollados desde inicios de la década de los 80's por Barto y Sutton.

En este pequeño texto vamos a explicar cuál es la importancia del Aprendizaje por Refuerzo y en particular el monumental trabajo de estos científicos. La inteligencia artificial moderna no se puede entender sin esta poderosa herramienta que como dice Yann LeCun es la cereza del pastel.El texto está dividido en las siguiente secciones:
- ¿Qué es el aprendizaje por refuerzo?
- ¿Dónde se ha utilizado el aprendizaje por refuerzo?
- ¿Cómo han contribuido Sutton y Barto al aprendizaje por refuerzo?
En el Colegio de Matemáticas Bourbaki nos esforzamos para que nuestros estudiantes sin importar cuál de los tracks que sigan dentro de nuestra oferta académica, siempre tengan la oportunidad de aprender sobre las distintas técnicas de aprendizaje por refuerzo. Al ser un área tan importante hemos preparado material relacionado con todos los siguientes métodos de aprendizaje por refuerzo:
- Value Iteration
- Temporal Difference
- Q-Learning
- SARSA
- Deep QL
- Double Depp Q-Learning
- Actor-Critic
- Trust Region Policy Optimization
- Proximal Policy Optimization
- Reinforcement Learning with Human Feedback
Les invitamos a conocer más detalles sobre cuál de los métodos de RL es más adecuado para sus intereses y aplicaciones.
¿Qué es el aprendizaje por refuerzo?
Antes de explicar la idea principal detrás del Aprendizaje por Refuerzo vamos a revisar un concepto aún más sencillo que nos ayudará a motivar la necesidad de RL. En Machine Learning existe un paradigma de aprendizaje llamado Aprendizaje Supervisado el cual es el más utilizado debido a la calidad de sus resultados y a la simpleza de su implementación. Desafortunadamente el aprendizaje supervisado tiene una debilidad que es el costo implícito de la base de datos con la que se entrena. Para explicar esto pensemos en el siguiente problema:
- Deseamos enseñarle a un jardinero inexperto cómo cuidar un jardín.
Si nos acercamos a este problema desde el punto de vista del aprendizaje supervisado el maestro debería de proporcionarle a estudiante un conjunto de instrucciones para distintos escenarios, por ejemplo:
- Cuando el pasto esté amarillo es necesario durante 10 minutos.
- Cuando una planta tenga sus hojas llenas de una plaga es necesario limpiarlas con tal producto.
- Cuando haya llovido durante la noche no es necesario regar el pasto con tanta agua.
- Cuando notes que hay una zona sin pasto es necesario agregar más tierra y semillas de pasto.
...
Si bien es cierto que los modelos de machine learning son capaces de aprender de este conjunto de instrucciones a pesar de no ser exhaustivo, podrán notar que la cantidad de instrucciones que le tendríamos que dar a un jardinero parece ser gigantesca si consideramos el inmenso número de variables que podrían cambiar la instrucción adecuada. Esto mismo pasa en muchos otros problemas como por ejemplo el juego de ajedrez, resulta terriblemente ineficaz estadísticamente hablando suponer que tendremos un conjunto de instrucciones lo suficientemente grande como para capturar el conocimiento experto del profesor.
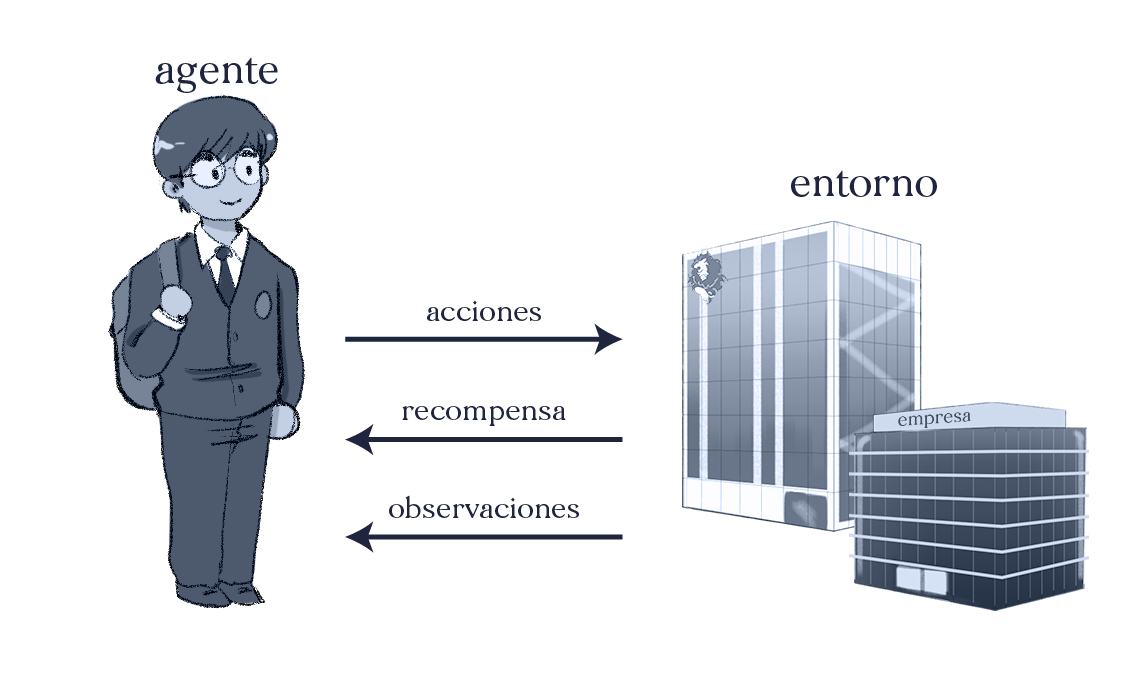
En lugar de lo anterior el aprendizaje por refuerzo va a concentrarse en definir una función que evalúe los posibles intentos del jardinero inexperto con el objetivo de permitirle interactuar con el ambiente y registrar sus fallos y aciertos; a esta función se le llama el refuerzo. Este proceso es el análogo del algoritmo de entrenamiento en machine learning supervisado. Notemos que en este caso el jardinero maestro solo está encargado de revisar la definición de la función de refuerzo, nunca le dice qué debería de hacer.
En una charla en 1947 Alan Turing sugirió lo siguiente:
What we want is a machine that can learn from experience...
Como lo notó Jeff Dean en la cita del premio Turing de este año, es muy probable que el Aprendizaje por Refuerzo lo haya logrado.
¿Dónde se ha utilizado el aprendizaje por refuerzo?
Existe una gran cantidad de problemas que se han resuelto utilizando aprendizaje por refuerzo, sería difícil enlistarlos todos. Con el fin de señalar algunas aplicaciones notables vamos a hablar sobre 4 casos notables en los que se ha utilizado Aprendizaje por Refuerzo.
AlphaGo
Posiblemente el caso de uso más famoso del aprendizaje por refuerzo es cuando el modelo construido por Google DeepMind llamado AlphaGo logró vencer al mejor jugador en la historia del Go Lee Sedol. Este hecho fue especialmente importante debido a la enorme dificultad que representa jugar Go en términos computacionales. Es sobresaliente que a raíz de este desarrollo, Google DeepMind fue capaz de disminuir en un 40% los costos generados por los sistemas de enfriamiento en sus datacenters.

Un robot capaz de armar un cubo de Rubik
Si bien es cierto que los modelos matemáticos para armar correctamente un cubo de rubik existen desde hace tiempo, hace unos años un robot físico fue capaz de armar por primera vez un cubo de rubik utilizando aprendizaje por refuerzo, esto significa que tuvo que considerar no solo las variables de la posición sino otras relacionadas con la destreza física de armar este cubo.

ChatGPT
Los chatbots que tanto nos han deslumbrado en los últimos años sería imposibles sin el uso de aprendizaje por refuerzo pues nos permite no tener que decidir cuál es la mejor respuesta a un prompt sino rankearlas con el objetivo de aprender cuál es la idónea.

¿Cómo han contribuido Sutton y Barto al aprendizaje por refuerzo?
Si bien es cierto que Sutton y Barton no son los únicos que han contribuido al desarrollo del aprendizaje por refuerzo, son sin lugar a dudas quienes han moldeado la versión moderna de estos métodos, enlistamos a continuación 6 referencias que desde nuestro punto de vista son indispensables:
A Unified Theory of Expectation in Classical and Instrumental Conditioning:
Esta es la tesis de licenciatura de Sutton bajo la dirección de Barto, como pueden ver en esta tesis aún no han madurado muchas de las ideas sin embargo ya se menciona por primera vez conceptos como la teoría de Iván Pávlov lo cual no es exactamente lo mismo al refuerzo.
Temporal credit assignment in reinforcement learning.
Este texto es la tesis de doctorado de Sutton bajo la dirección de Barto en la que se introducen propiamente los primeros algoritmos de aprendizaje por refuerzo incluido el de temporal difference. Para este trabajo las ecuaciones de Bellman fueron fundamentales como para la mayor parte de los algoritmos clásicos como Q-Learning.
A temporal Difference Model of Classical Conditioning
Si bien es cierto que la tésis de doctorado desarrolló los algoritmos de Temporal difference, en este artículo se revisan algunos detalles sutiles, esta exposición corresponde a la versión más actual de estos algoritmos.
Policy Gradient Methods for Reinforcement Learning with Function Approximation
El aprendizaje por refuerzo no habría logrado el éxito en tantos problemas difíciles sin el uso de las redes neuronales profundas, para poderlas en todo su esplendor es necesario el teorema de Policy Gradient el cual fue demostrado por primera vez en este artículo.
Reinforcement Learning: An Introduction
Este es el libro de referencia para aprender aprendizaje por refuerzo, en numerosas ocasiones le hemos recomendado a nuestros estudiantes este texto y también lo hemos regalado en eventos con el objetivo de diseminar el uso de RL.
Intrinsically Motivated Learning of Hierarchical Collections of Skills
Hace algunos años se descubrió que posiblemente el algoritmo de aprendizaje por refuerzo de temporal difference sea el utilizado por la dopamina en el cerebro, este es solo uno de los muchos trabajos relacionados con este tema.
¿Dónde aprender reinforcement learning?
En el Colegio de Matemáticas Bourbaki enseñamos con detalle las matemáticas y las bases para que nuestros estudiantes estén listos para aprender los modelos más avanzados de Inteligencia Artificial, Ciencia de Datos y Finanzas Cuantitativas. Estos son los dos cursos que están por comenzar y durarán todo el 2025
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas)..





