
Las matemáticas de los valores faltantes

El problema de los valores faltantes en la Ciencia de Datos es uno de los más crueles para quienes deben lidiar con información no disponible pues representa un gran reto tener que extraer alguna señal significativa.
Existen distintos métodos para solucionar el problema de los datos faltantes, algunos de ellos son increíblemente simples como por ejemplo sustituirlos por alguna media, moda o mediana. En el Colegio de Matemáticas Bourbaki enseñamos distintos métodos útiles para el estudio de los valores faltantes por ejemplo con factorización de matrices, método de Rubin, redes neuronales generativas o auto-encoders.
Debido a lo temprano que se debe de elegir un método para el procesamiento de este tipo de datos en el pipeline de un científico de datos, nuestro compromiso con la decisión que tomemos debe ser alto. No estamos hablando de algún hiper-parámetro del algoritmo de entrenamiento sino de la materia prima con el que vamos a realizar todo nuestro análisis.

En este artículo de nuestro querido Bourbakisme vamos a explicar algunas de las ideas generales de los valores faltantes desde el punto de vista matemático y mencionar un reciente teorema matemático publicado en el artículo What’s a good imputation to predict with missing values? el cual es uno de los pocos resultados teóricos sobre el tema. En este trabajo se demuestra entre otras cosas un teorema que garantiza la convergencia óptima de cualquier método de imputación infinitamente diferenciable previo al entrenamiento. Quienes deseen conocer los detalles más técnicos los invitamos a que revisen el artículo original.
Eliminar columnas o registros
Una posibilidad que rápidamente nos viene a la cabeza es excluir aquellos registros o columnas dentro de mi base de datos que desafortunadamente contengan valores faltantes. En el caso particular en el que sean pocos los registros (o columnas) con valores faltantes, este método es inocuo estadísticamente hablando.
Ya sea desde el punto de vista de la estadística clásica o de los modelos más sofisticados de Machine Learning, la promesa siempre es la misma:
Mientras mayor sea la cantidad de datos en nuestro dataset, mejor será la calidad de nuestras predicciones.
Lo anterior tiene algunas letras pequeñas cuando pensamos en resultados como la Ley de los Grandes Números o los teoremas de convergencia estilo PAC Learning que garantizan el enunciado anterior en el límite. Estos resultados garantizan que deshacernos de una pequeña parte de nuestros renglones no debe de ser muy dañino.

Desafortunadamente en la práctica no es posible pensar que los valores faltantes de un conjunto de datos se concentran en pocos renglones, lo natural será que estén distribuidos a lo largo de la base de datos entera.
Datasets como procesos generativos y los métodos de Rubin
Debido al comentario anterior, es necesario imaginar que nuestro problema no es uni-variado, lo cual es lo más común en Ciencia de Datos. Debido a lo anterior, es necesario imaginar al proceso generativo con el que se construyen las bases de datos como un vector (o tensor en algunos casos) aleatorio lo cual aumenta la complejidad estadística rápidamente.

Uno de los enfoques más utilizados para resolver el problema de la imputación de valores faltantes es el propuesto por el científico Donald Rubin quien propone realizar una simulación de posibles bases de datos que completen a nuestra base inicial antes de utilizar técnicas estadísticas para validar cuáles son los mejores valores.
Quienes deseen conocer más detalles sobre estos métodos les recomendamos que revisen el siguiente artículo en el que se cuentan las ideas principales.
Imputar y después entrenar es Bayes consistente

En el contexto particular de machine learning una pregunta inmediata que nos podríamos hacer es la siguiente:
¿Es suficiente con primero imputar datos y después entrenar a un modelo matemático o se debe de hacer en algún otro orden?
Siguiendo una idea muy similar a la que se utiliza en el Bayes Optimal Predictor de Machine Learning el cual utiliza a la distribución de nuestros datos, en el artículo que les mencionamos al inicio del texto, se propone un límite al cual debería de llegar una estrategia de imputación de valores.
El principal teorema de este trabajo enuncia que es posible converger a este límite de Bayes inclusive cuando nuestra estrategia de imputación de valores faltantes solo es utilizada antes del entrenamiento del modelo de machine learning.
Diferenciabilidad = universalidad
Además de lo anterior el artículo demuestra algo verdaderamente sorprendente: cualquier función de imputación de valores faltantes es convergente siempre y cuando sea una función infinitamente diferenciable.
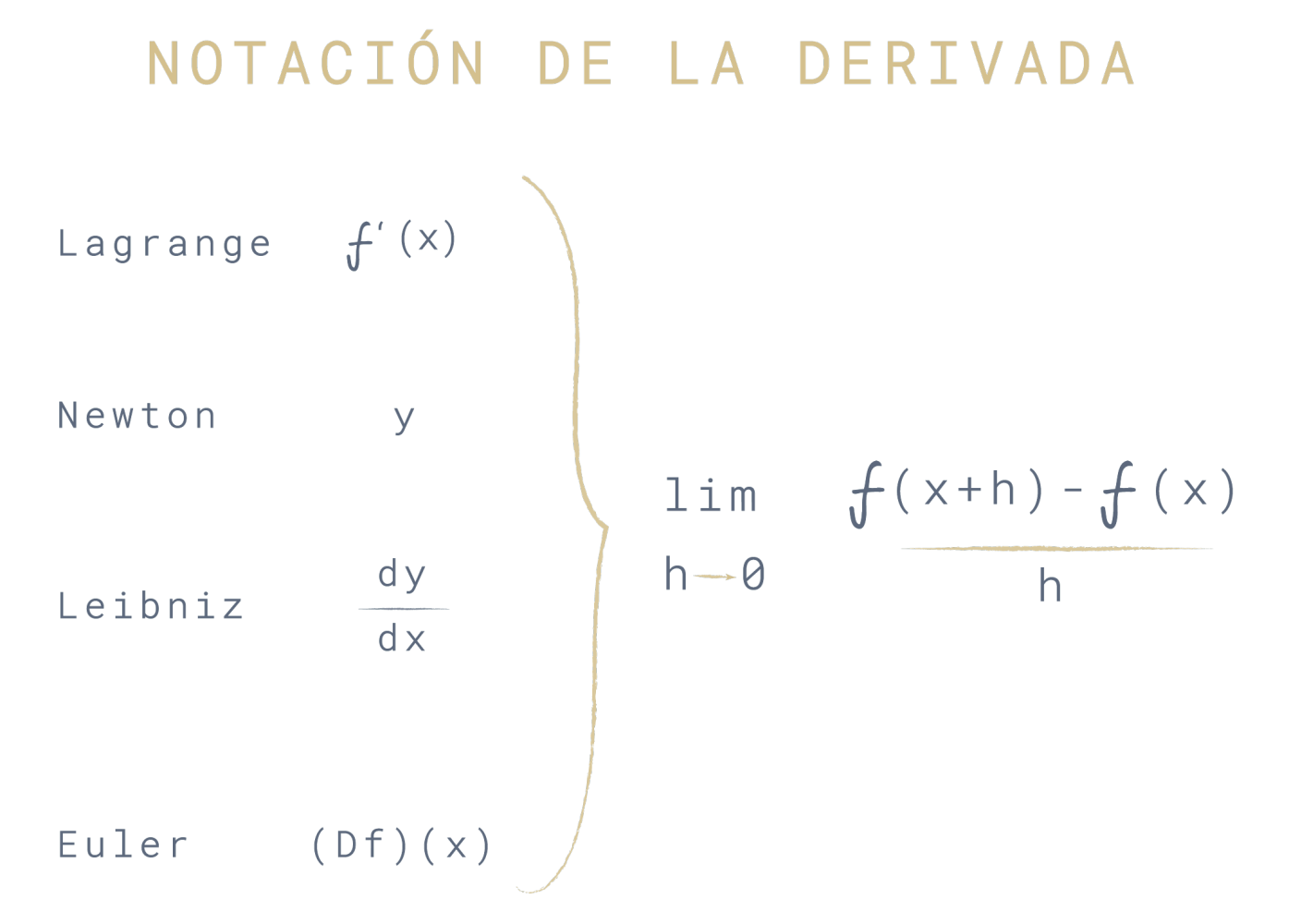
La función que a todos los valores faltantes le asigna el mismo valor (muchas veces cero) es una función infinitamente diferenciable por lo cual el teorema anterior garantiza que en el límite inclusive un método tan ingenuo podría funcionar.
Es importante mencionar que los teoremas límites no son suficientes para los practicioners de la ciencia de datos pues normalmente no garantizan cotas óptimas, el ejemplo perfecto de esto son el entrenamiento de las redes neuronales profundas.
¿Cómo aprender más matemáticas?
En el Colegio de Matemáticas Bourbaki enseñamos con detalle las matemáticas y los usos de las redes neuronales profundas, les invirtamos a revisar nuestra oferta académica para elegir el curso adecuado.
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).


Inferencia bayesiana (según T. Tao)

Jim Simons: topología, trading y filantropía
