
La hambruna de las grandes dimensiones en Ciencia de Datos
Este año el ganador del premio Abel fue el matemático francés Michel Talagrand, el premio que recibió es junto a la medalla Fields el más importante que podría recibir un matemático así que el trabajo de Talagrand es uno de los más sobresalientes de las últimas décadas.
En una edición pasada de nuestro querido Bourbakisme ya hablamos sobre algunas de las contribuciones de Talagrand sin embargo no entramos en demasiados detalles sobre la íntima relación que tienen estos trabajos con la Ciencia de Datos y en particular con la distribución de las bases de datos.

En esta semana dentro del Colegio de Matemáticas Bourbaki en numerosas ocasiones nos ha tocado explicarle a nuestros estudiantes cómo la alta dimensionalidad en los conjuntos de datos podría ser perjudicial para el desarrollo de los algoritmos basados en nociones de similitud. Debido a esto se nos ha ocurrido escribir un texto en el que estos conceptos se expliquen con mayor detalle.
Las naranjas sin naranja
El análogo en tres dimensiones de un círculo con radio uno es una esfera con radio uno, de la misma manera podemos definir una figura con cualquier cantidad de dimensiones que cumpla las propiedades fundamentales de un círculo o de una esfera. A saber, una esfera con d dimensiones es el conjunto de vectores cuyas coordenadas satisfacen las siguientes ecuaciones:

Si tuviéramos una naranja o una papa muy redonda en muchas dimensiones, esta sería la ecuación que lo determina. La siguiente ecuación determina el conjunto de puntos cercanos a la cáscara correspondiente:
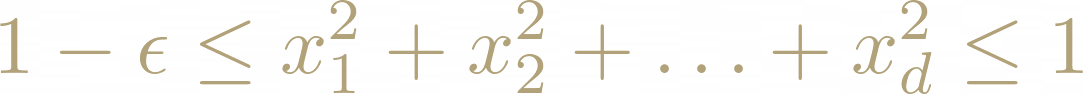
El valor de épsilon será el ancho de la cáscara y tanto para las naranjas como para las papas es natural imaginar que el volumen de estas cáscaras es insignificante con respecto al resto de la fruta (o verdura) correspondiente.
Increíblemente esto no ocurre en grandes dimensiones ya que si calculamos cuidadosamente los volúmenes incluyendo la cáscara y sin incluirla obtenemos la siguiente razón:

Aunque el valor de épsilon sea demasiado pequeño, cuando la dimensión del espacio es gigantesca, esta cantidad se acerca a cero y por lo tanto la mayor parte del volumen de una naranja o de una papa estarán en la cáscara. ¡No podremos comer casi nada! Este resultado es completamente contra-intuitivo.
Las desigualdades de concentración à la Talagrand
Un resultado matemático que no es inmediato pero que tampoco es demasiado complicado de demostrar es que la distribución uniforme dentro de una esfera es muy parecida a la distribución de un conjunto de datos cuyas coordenadas son gaussianas y cuya matriz de correlación es perfecta para los científicos de datos.

Este es solo uno de los resultados conocidos como las desigualdades de concentración de las medidas por las cuales Talagrand recibió el premio Abel. Es importante mencionar que estos resultados también tienen consecuencias positivas en Machine Learning relacionadas con la garantía de convergencia de algunos algoritmos.
Los algoritmos de similitud y sus fallas
El teorema anterior tiene una consecuencia negativa inmediata para los científicos de datos que desean utilizar a las medidas de similitud euclidianas (también ocurre algo similar con otras como la medida del coseno).

Imaginemos que hemos encontrado dos tipos de clientes lo suficientemente distintos entre sí, digamos A y B. Es común pensar que deseamos evaluar si otros clientes son parecidos a A o parecidos a B para decidir el tipo de productos que les vamos a ofrecer. Si construimos una esfera centrada en A por ejemplo, que tenga radio la distancia entre A y B, los teoremas de concentración nos dicen que prácticamente todos los clientes que podrían estar cerca de A, en realidad están tan alejados como B lo cual seguramente no es cierto en nuestro negocio.
Este mismo tipo de fenómenos se dispersan por casi todas las áreas de la ciencia de datos y son una de las principales razones por las cuales es un área muy complicada para las matemáticas.
Oferta académica del Colegio Bourbaki
Quienes deseen aprender más sobre las aplicaciones de este resultado a las finanzas cuantitativa los invitamos a conocer más sobre nuestra oferta académica.
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).


Bob Metcalfe y su Ethernet: premio Turing 2022

Ética para A... I.
