Few-shot learning = machine learning sin gradientes




¿Cómo puede ayudar un Large Language Model a reducir el tiempo que los trabajadores de una compañía utilizan en tareas repetitivas? Existen muchos ejemplos en los que los LLM pueden ayudarnos en nuestro día a día sin embargo antes de implementarlos es necesario hacer una cuidadosa evaluación de su desempeño.
Cuando los resultados no sean extremadamente buenos podríamos utilizar alguna técnica de calibrado o few-shot learning utilizando información a nuestro alcance. En los últimos meses gracias al éxito de los grandes modelos del lenguaje y en particular con el desarrollo de versiones a la medida de distintas industrias, se han popularizado métodos para mejorar el desempeño de estos modelos en tareas específicas.

En esta edición de nuestro boletín hablaremos sobre por qué resultados como Zero-Shot Learning son plausibles en un modelo de Machine Learning y cómo los métodos de Few-Shot learning pueden ayudarnos en algunas ocasiones. A diferencia de los métodos de Fine-Tuning, estas técnicas no van a modificar los parámetros de las redes neuronales por medio del cálculo de los gradientes, es decir sin ninguna iteración en el entrenamiento.
¿Zero-shot es evidente?
El caso de zero-shot learning es el más sorprendente para los estudiantes jóvenes de Ciencia de Datos. Comencemos con una pregunta muy sencilla:
Si un modelo de Machine Learning ha sido entrenado utilizando un conjunto de etiquetas Y, ¿es posible que el modelo prediga un resultado distinto a los valores Y?
Tal y como está planteada la pregunta parece imposible sin embargo la podemos re-plantear en un contexto completamente diferente.
Si un Chef ha sido entrenado para cocinar platillos utilizando animales que sí existen, ¿es posible que el cocinero sepa cómo cocinar platillos con dinosaurios?
Como podemos imaginarlo, aunque no hayamos visto un dinosaurio, ellos comparten algunas características con los animales que sí existen.
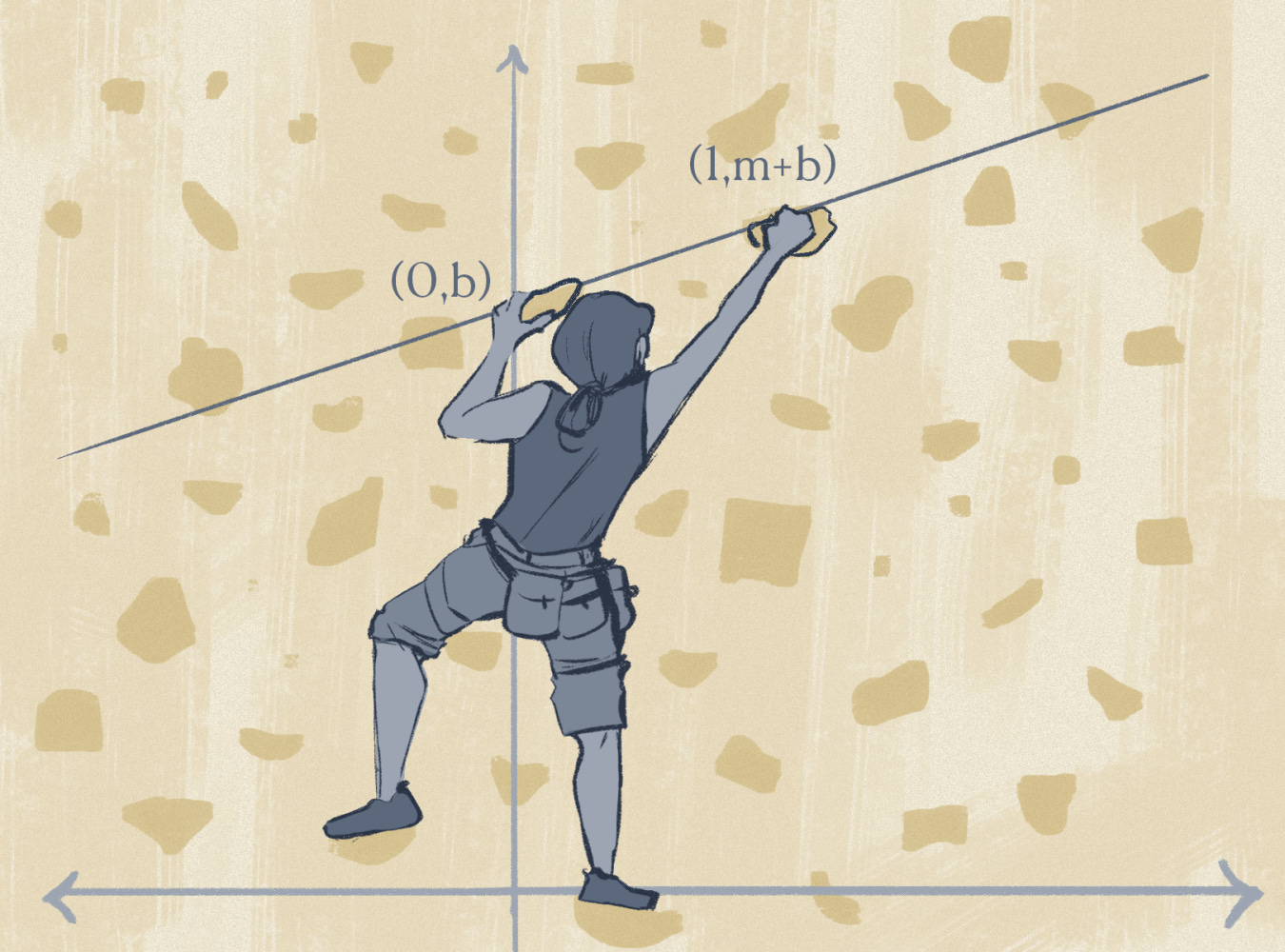
Veamos el ejemplo de una regresión lineal. Imaginemos un modelo matemático que solo ha visto casas con un valor menor o igual a 500,000 USD. Si introducimos al modelo entrenado una casa 10 veces más grande que el conjunto de casas en el entrenamiento, es razonable imaginar que el costo será considerablemente más grande y se saldrá del rango de los 500,000 USD.
La razón por la que el planteamiento de la pregunta anterior está incompleto es porque en realidad el conjunto Y no es un conjunto sin estructura, tiene un orden total y además dos operaciones aritméticas muy importantes.
NLP y zero-shot learning
Quienes estén familiarizados con los encajes de palabras (como GLOVE o Word2vec) estarán de acuerdo con que si nuestro objetivo es resolver un problema del estilo Masked Language Modeling, digamos para ser más específicos predecir el siguiente token, la siguiente versión de la pregunta anterior parece bastante posible:
Si un modelo de Machine Learning ha sido entrenado para predecir la siguiente palabra utilizando un conjunto de palabras Y, ¿es posible que el modelo prediga una palabra distinta a las palabras en Y?
Por supuesto que sí, imaginemos que el modelo ha sido entrenado con el siguiente conjunto supervisado:
- X = Después de batir las claras de huevo el
- Y = Panadero
Si el encaje de palabras que estamos utilizando incluye a la palabra repostero es perfectamente posible que la prediga utilizando el siguiente texto:
- X = Después de batir las claras de huevo y calentar el chocolate el
Evidentemente estamos utilizando la estructura del espacio latente en el que viven nuestras palabras. Recomiendo mucho el artículo en el que participó el célebre Geoffrey Hinton Zero-Shot Learning with Semantic Output Codes en el que se estudia desde un punto de vista matemático este problema.

En el ejemplo que tratan en ese trabajo, las variables explicativas son señales de las conexiones neuronales (las de verdad) en el cerebro de un ser humano al escuchar una palabra mientras que las variables objetivo son la palabra que se está escuchando.
Few-shot learning
Como se ha visto en muchas ocasiones, en los Grandes Modelos del Lenguaje algunas veces podríamos modificar nuestros Prompts con el objetivo de ayudarle al modelo para realizar mejores predicciones.

Además de la estructura de similitud en la variable objetivo, podemos utilizar otro tipo de relaciones que se han descubierto en el Procesamiento del Lenguaje Natural, a saber las analogías. Los modelos como GLOVE o Word2vec satisfacen la propiedad matemática de las analogías, es decir:
Si la relación entre las palabras A y B es la misma que entre las palabras V y W, entonces existe una similitud matemática entre los vectores de GLOVE para A-B y V-W.
Utilizando esta propiedad podemos construir un prompt de la forma:
Utilizando la información de V me gustaría que hagas una predicción similar a la que B es para A.
Afortunadamente los LLM mejorar sustancialmente su calidad utilizando este tipo de astucias.
Oferta académica del Colegio Bourbaki
Quienes deseen aprender más sobre las aplicaciones de este resultado a las finanzas cuantitativa los invitamos a conocer más sobre nuestra oferta académica.
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).





