
Correlaciones espurias en Big Data y el teorema de Van der Waerden

Hace algunos años en uno de los seminarios que organizamos en el Colegio de Matemáticas Bourbaki decidí exponer un artículo titulado The Deluge of Spurious Correlations in Big Data el cual me parece increíblemente interesante y al mismo tiempo divertidísimo.
En este artículo se utiliza tanto Teoría Ergódica como Teoría de Ramsey para probar matemáticamente la existencia (y en algunos casos abundancia) de las llamadas correlaciones espurias. Informalmente una correlación espuria es una trampa a la que están expuestos los científicos de datos, analistas o quants que no conocen lo suficiente sobre la naturaleza de los problemas y se dejan llevar por mediciones estadísticas. A lo largo de este texto diremos que una correlación es espuria cuando no modela ninguna relación consistente.

Un buen ejemplo de esto se presenta en el artículo: existe una relación estadística entre el número de matrimonios en Kentucky y el número de personas ahogadas al caer en un barco de pesca. Estadísticamente sí existe una relación entre estas dos cantidades sin embargo no hay manera razonable de creer que esta correlación pueda ser de utilidad.
En esta edición de nuestro Bourbakisme me gustaría darles una breve explicación del famoso teorema de Van der Waerden y su importancia en la Teoría de la Combinatoria, así como explicar cómo este teorema demuestra matemáticamente la existencia de correlaciones lineales entre fenómenos completamente arbitrarios.
El teorema de Van der Waerden
En el mismo texto que estamos analizando se presenta a la teoría de Ramsey citando un artículo de Scientific American como la prueba del siguiente enunciado:
El completo desorden es imposible. Todos los conjuntos suficientemente grandes exhiben alguna regularidad en sus patrones.
Esta idea es la base de la tésis en la que se refuta que la ciencia de datos pueda ser un sustituto de la actividad científica o empresarial pues algunos patrones podrían aparecer solo por razones del tamaño de nuestras bases de datos.

Ahora enunciaremos formalmente el teorema pero antes vamos a repasar el concepto matemático de una progresión aritmética. Digamos que tenemos una familia de números naturales:
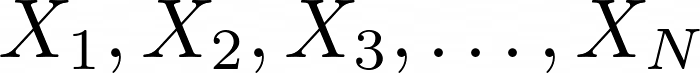
Diremos que ellos son una progresión aritmética cuando existan dos betas tales que:
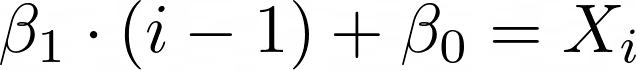
Por ejemplo la siguiente secuencia de N = 9 números es una progresión aritmética: 1, 5, 9, 13, 17, 21, 25, 29, 33. Dejamos como ejercicio a los lectores encontrar los valores de beta correspondientes.
Notemos que si conocemos los valores de las betas, es muy fácil predecir cuando un número X es parte o no de esa sucesión aritmética, simplemente debemos de restarle beta cero y dividir sobre beta uno. Si el resultado es un entero entonces ese X será parte del a sucesión aritmética. Esta observación es fundamental.
El teorema de Van der Waerden dice lo siguiente:
Supongamos que K y N son dos números arbitrarios. Entonces existe un número M de tal manera que cualquier grupo de elementos indexados con los números X del 1 al M y cualquier función que etiquete a estos elementos en K clases distintas: contiene por lo menos un subconjunto de elementos de tamaño N, cuyos índices X satisfacen ser una progresión aritmética y además tengan la misma etiqueta.
Sabemos que el enunciado podría ser bastante abstracto sin embargo a continuación vamos a ejemplificar qué podría significar esto en una base de datos. Imaginemos por el momento que nuestros M elementos son literalmente los números del 1 al M y que ellos han sido coloreados en K=2 clases distintas de manera arbitraria. El teorema anterior nos garantiza la existencia de un comportamiento regular (progresión aritmética) suficientemente frecuente (el número N que hemos elegido al inicio) de números con el mismo color.

Es importante mencionar que el tamaño real de M en función de los parámetros K y N es muy difícil de calcularse, en la actualidad la mejor cota que existe la ha demostrado el matemático inglés Timothy Gowers:
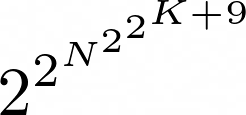
Aplicación para Big Data
Gracias al teorema anterior se puede demostrar matemáticamente la siguiente afirmación, es importante mencionar que en el artículo original se utiliza la palabra correlaciones sin embargo entendemos que esto podría sesgar mucho a nuestra audiencia y que lo interpreten por ejemplo como una correlación de Pearsson en cuyo caso es un poco más difícil interpretar al teorema de Van der Waerden.
Cualquier relación estadística entre dos propiedades, por ridícula que parezca, es posible encontrarla tantas veces como uno lo desee en una base de datos. Lo anterior es siempre y cuando la base de datos tenga un tamaño mínimo.
El punto clave en el enunciado anterior es que la base de datos podría ser increíblemente grande y evidentemente esto será prohibitivo inclusive, para nuestra época en la que la cantidad de datos generados crece a un ritmo inimaginable. Debido a que el cálculo explícito de los números de Van der Waerden es un problema abierto, no podemos decir mucho sobre si estas correlaciones ya podrían estar apareciendo en nuestros datasets.

Ahora traduzcamos el teorema de Van der Waerden pensando en un sistema de recomendación:
- Digamos que nuestra población total serán todas las ventas en línea de algún producto o algún servicio.
- Supongamos que N es un tamaño lo suficientemente grande a partir del cual estamos contentos con una relación estadística. Si miles de millones de nuestros registros satisfacen una propiedad, es razonable concluir que esa propiedad está relacionada con esa población. ¿No es cierto?
- Supongamos que vamos a fijar K relaciones completamente absurdas para las compras en línea. Una familia de etiquetas absurdas sería la siguiente: dada una compra, la etiquetaremos con la pareja de signos zodiacales de quien realizó la compra y de quien fabricó el producto. Una de estas etiquetas podría ser por ejemplo Libra-Sagitario.
- El teorema de Van der Waerden afirma que existe o existirá algún momento en el que se hayan realizado tantas compras por internet que el subconjunto de compras por internet de alguna pareja de signos del zodiaco cumple lo siguiente.
- Existen por lo menos N ventas en línea de productos comprados y vendidos por personas con alguna pareja de signos zodiacales, digamos que fuera Libra-Sagitario. Recuerden que estamos suponiendo que esta cantidad es enorme.
- Es posible identificar en nuestra base de datos los índices X (las variables explicativas) de esos registros únicamente evaluando si pertenecen a una progresión aritmética. Como estamos suponiendo que hay N de ellos, es muy probable que un modelo de machine learning lo podría detectar.
- Habremos concluido que para inducir que con el signo Libra compre un producto, debemos de recomendarle aquellos que hayan sido producidos por Sagitarios.
¿Dónde aprender más?
En el Colegio de Matemáticas Bourbaki enseñamos con detalle las matemáticas de los distintos aspectos de la Ciencia de Datos y la Inteligencia Artificial. Todos los perfiles y necesidades son bienvenidos. Compartimos con ustedes algunos de nuestros temarios de cursos por iniciar:
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).


Lo mejor del 2023 en IA (7 artículos formidables)

Compañías calificadoras de bonos
