17 ecuaciones que cambiaron Machine Learning


Alfonso Ruiz


Hace más de un año lanzamos nuestro curso propedéutico 17 ecuaciones que cambiaron Machine Learning y un poco después junto a Gerardo Hernandez-del-Valle del 17 ecuaciones que cambiaron los mercados financieros. En ambos casos estuvimos evidentemente inspirados en el espectacular libro "In Pursuit of the Unknown: 17 Equations That Changed the World" de Ian Stewart.
Con el objetivo de llegar a una comunidad más amplia que la de nuestros estudiantes, hemos decidido compartirle a toda nuestra comunidad una parte de este material con el deseo de mejorar el conocimiento matemático de los practicantes de Machine Learning.
Así mismo aprovechamos para anunciar que la semana siguiente inauguraremos el curso 17 ecuaciones de pérdida que cambiaron la inteligencia artificial. Este contenido será exclusivamente para nuestros estudiantes.
Factorización de matrices en valores singulares, 1873
Pensemos en el caso de Netflix y su base de datos, donde para cada usuario conocemos las películas o series que han visto hasta el momento. El principal problema de esta base de datos es que la gran mayoría de los registros tienen menos del uno porciento de registros nulos, por lo que es imposible matemáticamente hablando encontrar semejanzas entre ellos. Gracias a los teoremas de factorización de matrices es posible descomponer la base de datos de Netflix en tres bases de datos con tamaños mucho menores que no solo permiten calcular semejanzas entre usuarios, sino también entre películas e incluso entre películas y usuarios, lo cual es muy útil para construir sistemas de recomendación.
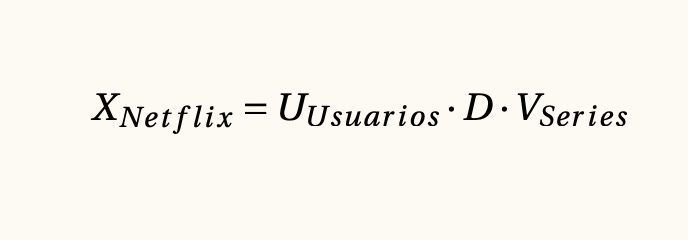
Perceptrón multi-capa y redes neuronales, 1943
El perceptrón con una sola capa es un modelo matemático que realiza predicciones por medio de un promedio ponderado de las características de nuestros datos. La ecuación del perceptrón multi-capa propone un comportamiento no-lineal por medio de concatenación y composición de perceptrones multi-capa. Las poderosas redes neuronales profundas que se utilizan en tan diversas áreas de la ciencia de datos utilizan estas fórmulas para aproximar mejor a las variables.
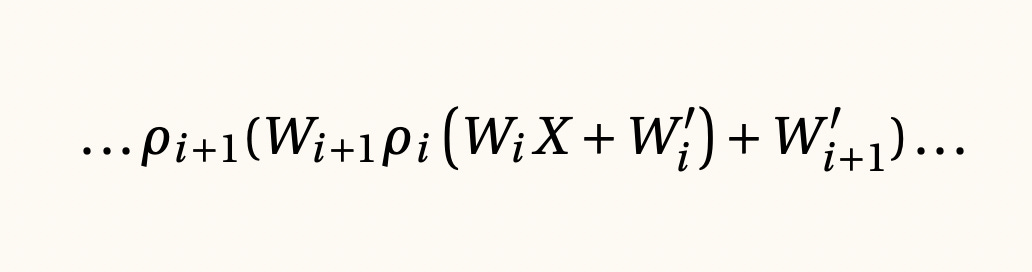
Entropía y entropía cruzada para distribuciones de probabilidad, 1948
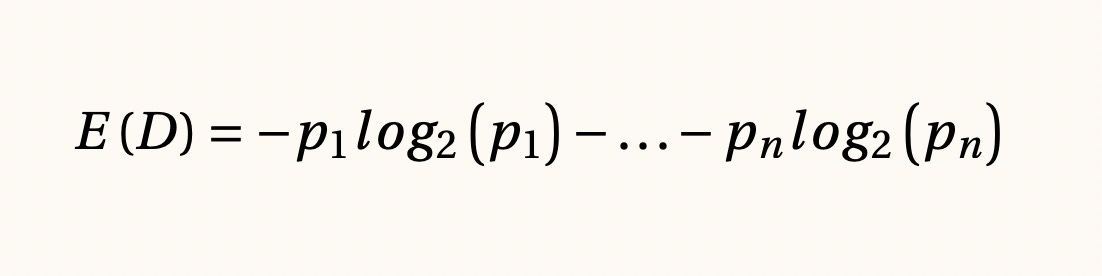
Supongamos que D es una muestra de nuestra población que satisface ciertas características fijas. Por ejemplo, podríamos pensar en características demográficas. Si deseamos segmentar a esta población en n grupos distintos, el cálculo de la entropía nos permite valorar la importancia de estas características. La entropía cruzada permite calcular la diferencia entre dos hipótesis.
Fórmula de Bayes e inferencia bayesiana, 1763
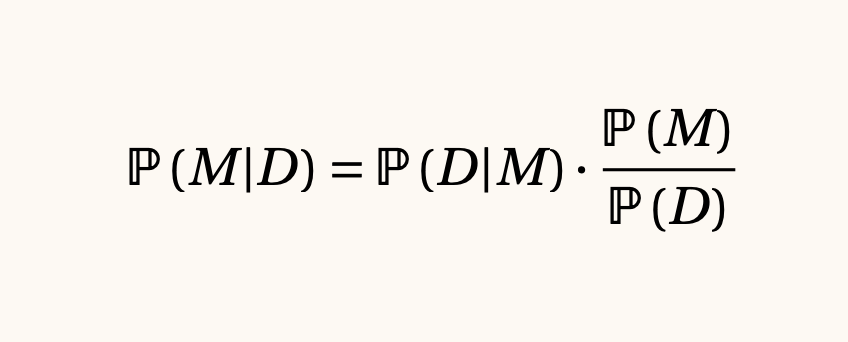
En algunos casos, el lado derecho de la ecuación es sencillo de calcular e inclusive podemos añadir conocimiento de experto sobre el problema para reducir un poco el espacio de búsqueda.
Márgenes entre clases y máquinas de soporte vectorial, 1992
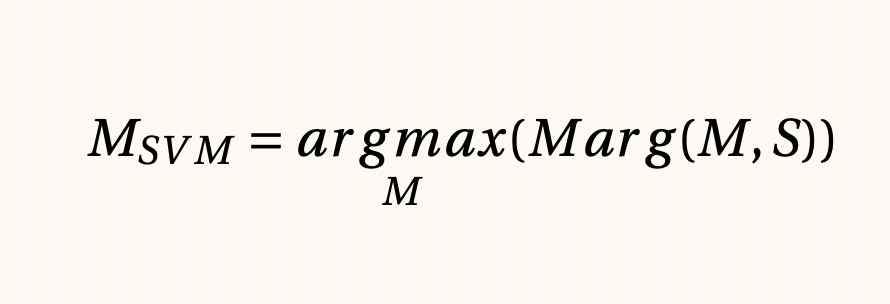
Un enfoque clásico en machine learning es buscar aquel modelo que cometa la menor cantidad de errores en nuestra base de datos D. Las máquinas de soporte vectorial proponen una manera distinta para encontrar estos patrones: concentrarse en buscar aquel modelo que se aleje simultáneamente de los registros de una clase respecto a la otra.
Descomposición del Error cuadrático medio como trade-off entre varianza y sesgo, 1805 & 1991
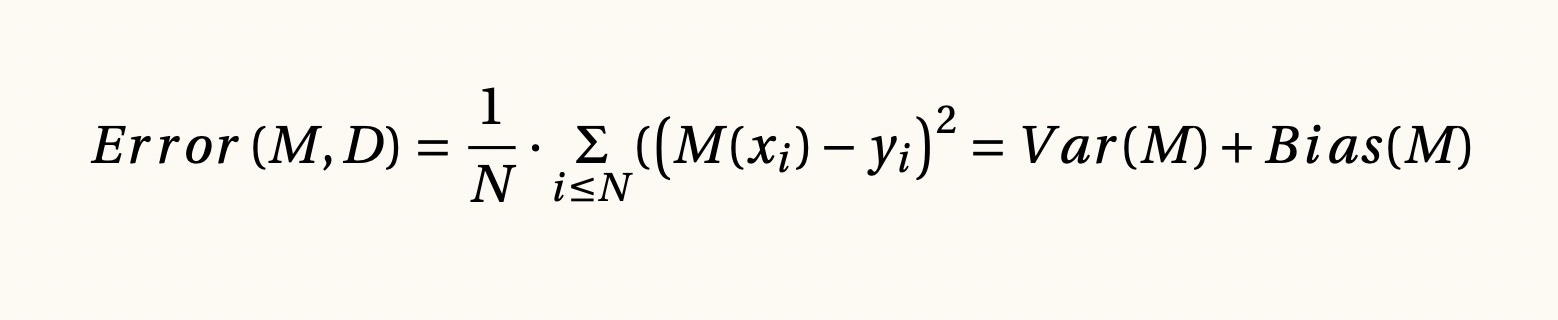
Para el caso en el que supongamos que nuestro modelo M es lineal, es decir, cuando la predicción es un promedio ponderado de las características de cada transacción, entonces podemos interpretar al primer sumando como la varianza de los pesos durante el entrenamiento y al segundo como el ruido el cual tradicionalmente es gaussiano. Esta descomposición nos permite comprender el dilema entre el ajuste y el sobre-ajuste de los modelos en ciencia de datos.
Funciones de activación sigmoide y soft-max, 1858
Uno de los problemas más difíciles en ciencia de datos es el de encontrar una explicación a los modelos matemáticos entrenados con bases de datos que se pueda traducir fácilmente en términos simples y de preferencia amigables con los usuarios. Ya hemos hablado de los modelos lineales, los cuales tienen grandes ventajas en este sentido, aunque otras desventajas como un gran error de aproximación para fenómenos más complejos y en particular no-lineales. Una de las herramientas más poderosas para resolver este problema son las funciones de activación conocidas como sigmoides o soft-max, las cuales son la base de las regresiones logísticas y nos permiten explicar con transparencia el origen de una predicción.
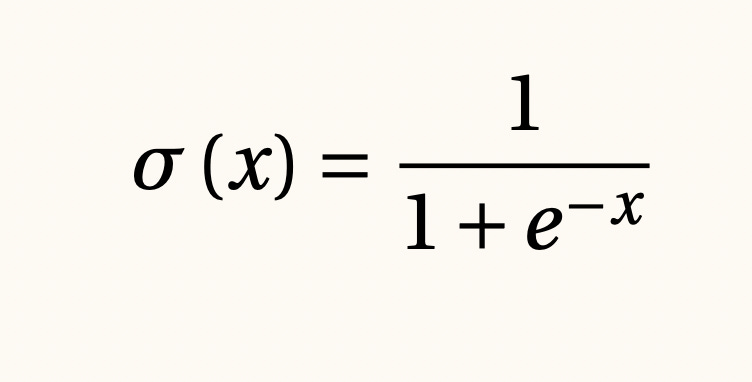
Regularizador de Tychonov y métodos dispersos, 1970
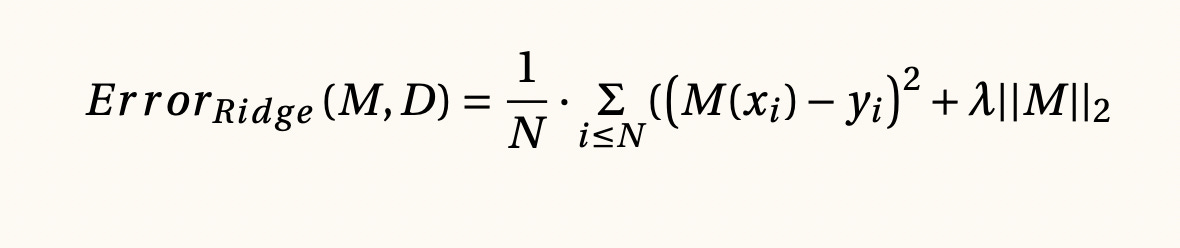
La ecuación anterior corresponde a la regularización Tychonov o Ridge y al modificar la última parte de la fórmula introducimos otras técnicas como los métodos dispersos tipo lasso, entre otros. En este caso estamos utilizando el error cuadrático medio, pero también es posible hacerlo mediante otras métricas.
Ley de los grandes números para procesos estacionarios, 1539
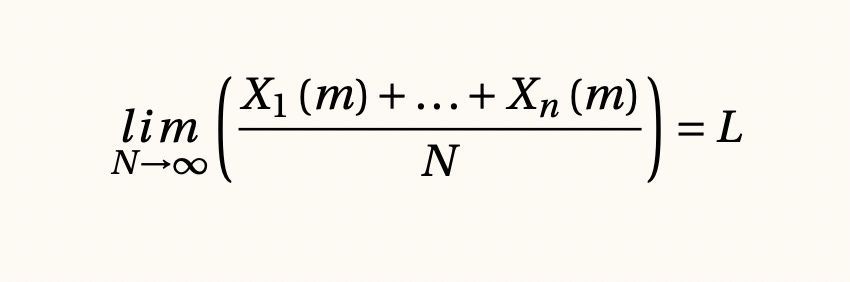
Dentro de los procesos estacionarios están tanto el ruido blanco como las cadenas de Markov e incluso los procesos ARIMA para series de tiempo. Estos casos corresponden a las siguientes intuiciones sobre la base de datos: muestreos estadísticamente representativos, procesos con memoria de corto plazo y series de tiempo sin tendencia o temporalidad, respectivamente.
Distribución gaussiana y el teorema central de Lévy, 1920
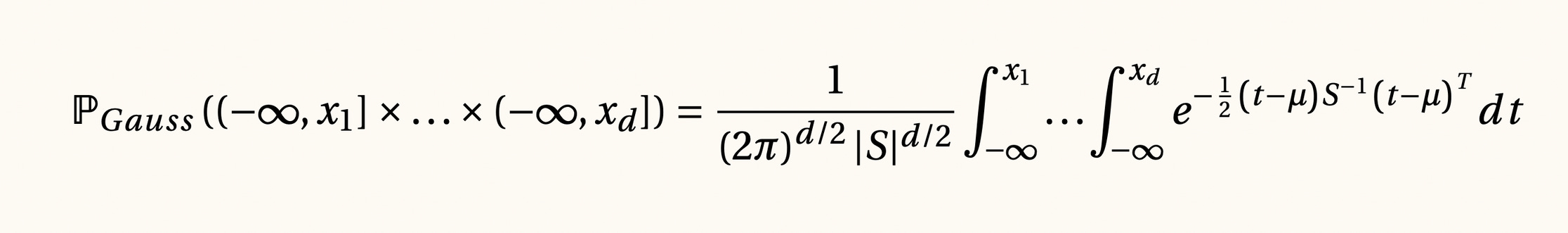
El teorema del límite central asegura que los errores que comete la aproximación de la ley de los grandes números en el punto anterior siempre serán gaussianos. Este teorema permite definir intervalos de confianza, los cuales están sujetos al cumplimiento de las hipótesis sobre la base de datos.
Algoritmo del gradiente descendente, 1847

El proceso del entrenamiento de los modelos utilizando bases de datos es un proceso complicado para el cual es necesario tener algoritmos que aproximen a nuestros datos eficazmente. Una de las grandes ideas matemáticas utilizadas en machine learning fue propuesta por Cauchy como método de optimización de las funciones de error. La idea intuitiva detrás de este algoritmo es la siguiente: si un modelo comete un error en nuestro conjunto de entrenamiento y calculamos la derivada de este error, al restarle iterativamente esta derivada estamos disminuiremos el error en las siguientes iteraciones.
Ecuaciones de Bellman y aprendizaje por refuerzo, 1953
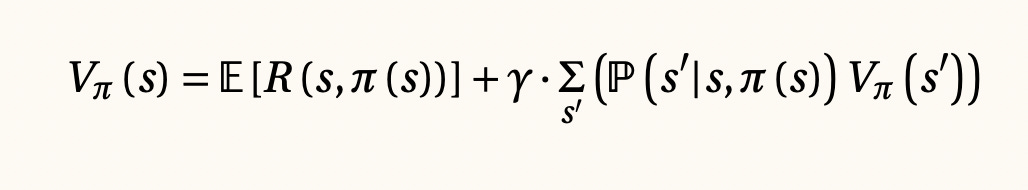
Gracias a esta ecuación es posible reducir el espacio de búsqueda donde encontramos las estrategias óptimas y así vencer lo que se conoce como la maldición de la dimensión. Estas ecuaciones han permitido construir modelos de inteligencia artificial verdaderamente poderosos.
Cross-correlation o convoluciones entre tensores, 1807
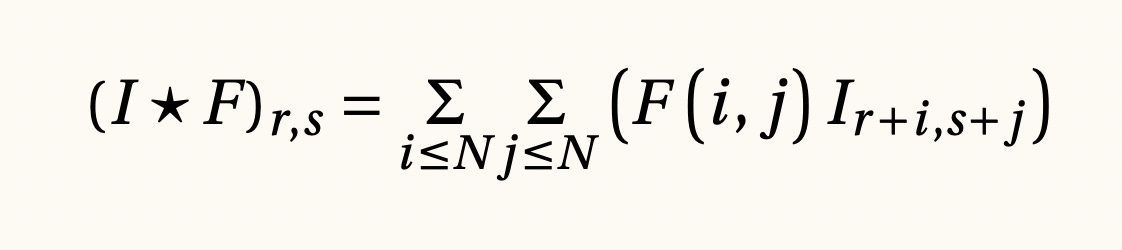
Supongamos que tenemos una imagen I a la cual queremos aplicarle un filtro F. Los objetivos de hacer esto podrían ser muy diversos, pero una de las intuiciones más útiles es porque queremos comprimir la información. Para este caso y muchos otros como la detección de objetos, por ejemplo, las correlaciones son operaciones matemáticas muy importantes que promedian los píxeles de una imagen siguiendo una regla constante a lo largo y alto de la imagen.
Función de pérdida adversarial para modelos generativos, 2014
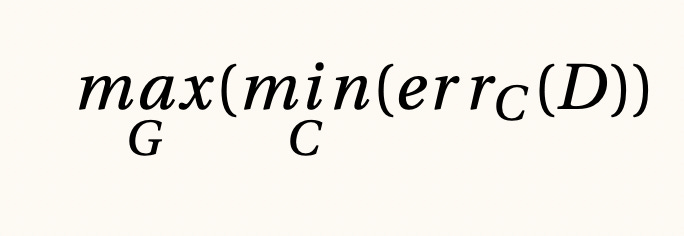
Las tareas generativas dentro de machine learning son muy complicadas, pues requieren aproximar funciones. Al tratar inteligencia artificial estas funciones se vuelven muy complejas, como el caso de las imágenes, en donde tenemos tantos grados de libertad como píxeles. Una manera muy inteligente para optimizar a los modelos generativos es mediante la ayuda de un modelo de clasificación supervisado. La idea general detrás de las Generative Adversarial Networks consiste en simultáneamente construir una base de datos donde, por definición, los registros generados son falsos y los de una base de datos fija serán los únicos verdaderos. La función de optimización en este caso coincide con un juego de suma cero, donde lo que gana un modelo de clasificación es lo que pierde el modelo generativo y viceversa.
Memoria de largo plazo y modelos recurrentes, 1999
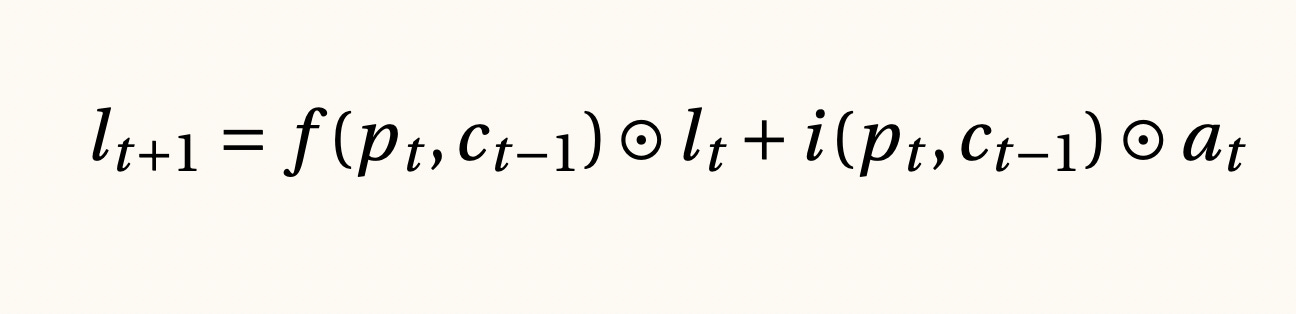
Así como las convoluciones son una operación matemática que permite inducir un sesgo sobre las operaciones entre imágenes, el procesamiento del lenguaje natural y las series de tiempo requieren que las redes neuronales tengan mejores arquitecturas que se amolden a la estructura de los datos. Las redes neuronales recurrentes modernas proponen un método para que las memorias de largo y corto plazo simpaticen y se puedan encontrar correlaciones largas y cortas al mismo tiempo. Semánticamente, lo anterior es muy importante, pues tanto las palabras lejanas como las cercanas pueden tener alguna importancia en nuestros textos.
Regla de la cadena y backpropagation, 1986
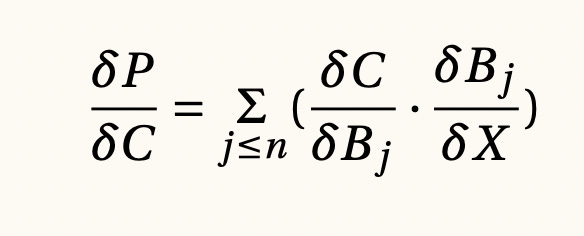
Las redes neuronales profundas pueden tener incluso trillones de parámetros que se entrenarán mediante un algoritmo conocido como backpropagation. Este algoritmo hace una elección inteligente y eficaz del cálculo de las derivadas que se harán para implementar el método del gradiente. Recordemos desde la fórmula de los perceptrones, pero también para el caso de las redes convolucionales y recurrentes, que las iteraciones entre distintas capas buscan aumentar la capacidad expresiva de los modelos, lo cual no tiene que ser necesariamente fácil desde un punto de vista computacional.
Mecanismo de atención, 2017
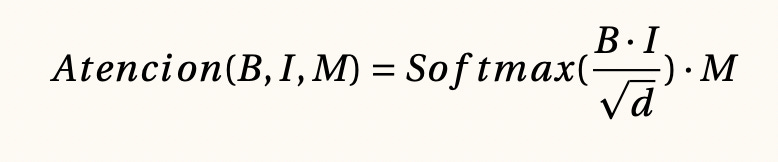
Supongamos que deseamos que un modelo de inteligencia artificial aprenda a buscar información dinámicamente utilizando algunos casos en los que buscó información exitosamente. Existe una arquitectura que permite realizar esto y es conocido como el mecanismo de atención, la ecuación fundamental la mostramos a continuación y en este caso podemos entender a B como aquello que estamos buscando en la memoria M mientras que I serán las instrucciones dinámicas que aprenderá el modelo de inteligencia artificial. En el caso del texto esta ecuación es muy importante pues permite realizar búsquedas en partes anteriores de nuestros textos.
¿Cómo aprender más sobre estos temas?
En el Colegio de Matemáticas Bourbaki enseñamos con detalle las matemáticas y los usos de las redes neuronales profundas, les invirtamos a revisar nuestra oferta académica para elegir el curso adecuado.
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).





